AI News
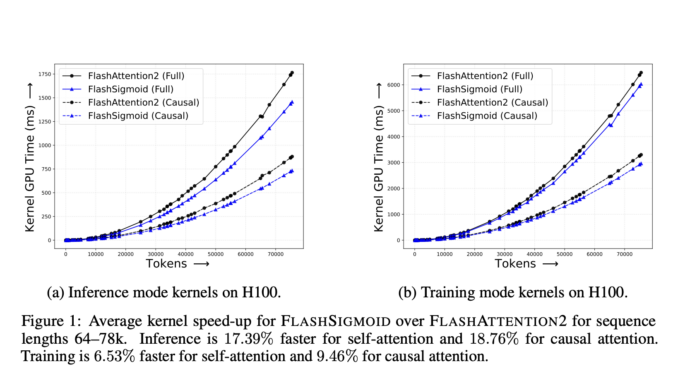
FlashSigmoid: A Hardware-Aware and Memory-Efficient Implementation of Sigmoid Attention Yielding a 17% Inference Kernel Speed-Up over FlashAttention-2 on H100 GPUs
Large Language Models (LLMs) have gained significant prominence in modern machine learning, largely due to the attention mechanism. This mechanism employs a sequence-to-sequence mapping to construct context-aware token representations. Traditionally, attention relies on the softmax […]